D*
D* (تلفظ "دی استار") هر یک از سه الگوریتم جستجوی افزایشی زیر است:
- D* اصلی،[۱] توسط آنتونی استنتز، یک الگوریتم جستجوی افزایشی آگاهانه است.
- D* متمرکز[۲] یک الگوریتم جستجوی (اکتشافی) افزایشی آگاهانه توسط آنتونی استنتز است که ایدههای A *[۳] و *D اصلی را ترکیب میکند. *D متمرکز ناشی از توسعه بیشتر *D اصلی است.
- D* Lite[۴] یک الگوریتم جستجوی اکتشافی افزایشی توسط Sven Koenig و Maxim Likhachev است که بر اساس *LPA بنا شدهاست،[۵] یک الگوریتم جستجوی اکتشافی افزایشی است که ایدههای A* و Dynamic SWSF-FP را ترکیب میکند.[۶]
هر سهٔ این الگوریتمهای جستجو مسائل برنامهریزی مسیر مبتنی بر فرض را حل میکنند، از جمله برنامهریزی با فرض فضای آزاد،[۷] که در آن یک ربات باید در یک زمین ناشناخته به مختصات هدف داده شده برود. که در مورد قسمت ناشناخته زمین فرضیاتی ارائه میشود (به عنوان مثال: هیچ مانعی در زمین وجود ندارد) و ربات کوتاهترین مسیر را از مختصات فعلی خود به مختصات هدف تحت این مفروضات مییابد. سپس ربات مسیر را دنبال میکند. هنگامی که اطلاعات نقشه جدید (مانند موانع ناشناخته قبلی) را مشاهده میکند، اطلاعات را به نقشه خود اضافه میکند و در صورت لزوم کوتاهترین مسیر جدید را از مختصات فعلی خود به مختصات هدف داده شده دوباره برنامهریزی میکند. این فرایند را تکرار میکند تا زمانی که به مختصات هدف برسد یا تعیین کند که نمیتوان به مختصات هدف رسید. هنگام عبور از زمین ناشناخته، موانع جدید ممکن است بهطور مکرر کشف شوند، بنابراین این برنامهریزی باید سریع باشد. الگوریتمهای جستجوی افزایشی (آگاهانه) سرعت جستجو را برای دنبالههایی از مشکلات جستجو مشابه با استفاده از تجربه مشکلات قبلی برای تسریع در جستجوی مورد فعلی افزایش میدهند. با فرض تغییر نکردن مختصات هدف، هر سه الگوریتم جستجو از جستجوی *A مکرر کارآمدتر هستند.
D* و انواع آن بهطور گستردهای برای رباتهای سیار و ناوبری وسیله نقلیه خودمختار استفاده میشوند. سیستمهای فعلی معمولاً بیشتر از D* Lite یا D* Focused مبتنی بر D* Lite هستند. در حقیقت، حتی آزمایشگاه استنتز در برخی از پیادهسازیها از D* Lite به جای *D استفاده میکند.[۸] چنین سیستمهای ناوبری شامل یک سیستم نمونه آزمایشی که در مریخ نوردهای Opportunity و Spirit و سیستم ناوبری برنده در DARPA Urban Challenge تست شدهاند که هر دو در دانشگاه کارنگی ملون توسعه یافتهاند.
D* اصلی توسط آنتونی استنتز در سال ۱۹۹۴ معرفی شد. نام *D از اصطلاح "*Dynamic A" آمدهاست،[۲] زیرا الگوریتم مانند *A رفتار میکند با این تفاوت که هنگام اجرای الگوریتم هزینههای قوس میتوانند تغییر کند.
عملکرد
[ویرایش]عملکرد اساسی *D در زیر بیان شدهاست.
مانند الگوریتم Dijkstra و *A، الگوریتم *D لیستی از گرههای مورد ارزیابی را نگهداری میکند، معروف به "لیست OPEN". گرهها به عنوان یکی از چندین حالت زیر مشخص شدهاند:
- جدید، یعنی هرگز در لیست OPEN قرار نگرفتهاست
- OPEN، یعنی در حال حاضر در لیست OPEN است
- CLOSED، یعنی دیگر در لیست OPEN نیست
- RAISE، نشان میدهد هزینه آن بالاتر از هزینه آخرین باری که در لیست OPEN بودهاست
- LOWER، نشان میدهد هزینه آن کمتر از هزینه آخرین باری است که در لیست OPEN قرار داشت
گسترش (تابع)
[ویرایش]این الگوریتم با تکرار عملیات انتخاب یک گره از لیست OPEN و ارزیابی آن کار میکند. سپس تغییرات گره را در همه گرههای همسایه منتشر کرده و در لیست OPEN قرار میدهد. این فرایند انتشار "گسترش" نامیده میشود. برخلاف *A متعارف، که مسیر را از ابتدا تا انتها دنبال میکند، *D با جستجوی عقبگرد از گره هدف شروع میشود. هر گره توسعه یافته دارای یک "backpointer" است که به گره بعدی منتهی به هدف اشاره دارد و هر گره هزینه دقیق رسیدن به هدف را میداند. وقتی گره شروع گره ای است که در مرحله بعدی گسترش مییابد، الگوریتم به پایان میرسد و میتوان با دنبال کردن نشانگرهای عقب("backpointers")، مسیر رسیدن به هدف را پیدا کرد.
-
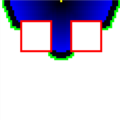 توسعه در حال انجام است. گره پایان (زرد) در وسط ردیف بالای نقاط قرار دارد و گره شروع در وسط ردیف پایین قرار دارد. رنگ قرمز نشان دهنده مانع است. رنگ سیاه/ آبی گرههای منبسط شده را نشان میدهند (روشنایی نشان دهنده هزینه است). رنگ سبز گرههایی را نشان میدهد که در حال گسترش هستند.
توسعه در حال انجام است. گره پایان (زرد) در وسط ردیف بالای نقاط قرار دارد و گره شروع در وسط ردیف پایین قرار دارد. رنگ قرمز نشان دهنده مانع است. رنگ سیاه/ آبی گرههای منبسط شده را نشان میدهند (روشنایی نشان دهنده هزینه است). رنگ سبز گرههایی را نشان میدهد که در حال گسترش هستند. -
 توسعه به پایان رسیده.و مسیر به رنگ فیروزه ای مشخص شدهاست.
توسعه به پایان رسیده.و مسیر به رنگ فیروزه ای مشخص شدهاست.


رسیدگی به موانع
[ویرایش]وقتی مانع در مسیر مورد نظر شناسایی شد، تمام نقاطی که تحت تأثیر قرار میگیرند با برچسب RAISE مشخص شده و دوباره در لیست OPEN قرار میگیرند. قبل از اینکه گره RAISED هزینه اش افزایش یابد، الگوریتم همسایگان خود را بررسی میکند و بررسی میکند که آیا میتواند هزینه گره را کاهش دهد. در غیر اینصورت، حالت RAISE به تمام فرزندان گرهها، یعنی گرههایی که دارای نشانههای برگشتی هستند، انتشار مییابد. سپس این گرهها ارزیابی شده و حالت RAISE منتقل شده و موجی را تشکیل میدهند. هنگامی که یک گره RAISED میتواند کاهش یابد، قسمت داخلی آن به روز میشود و وضعیت LOWER را به همسایگان خود منتقل میکند. این امواج RAISE و LOWER قلب *D هستند.
بوسیله این نکته، از «لمس شدن» یک سری از نقاط توسط امواج جلوگیری میشود؛ بنابراین الگوریتم فقط در نقاطی که در تغییر هزینه تأثیر دارند کار کردهاست.
-
 مانعی اضافه شدهاست (با رنگ قرمز) و گرههایی با برچسب RAISE (به رنگ زرد) مشخص شدهاند.
مانعی اضافه شدهاست (با رنگ قرمز) و گرههایی با برچسب RAISE (به رنگ زرد) مشخص شدهاند. -
 توسعه در حال انجام است. رنگ زرد گرههایی را نشان میدهد که با RAISE مشخص شدهاند، و رنگ سبز نشان دهنده گرههایی است که با LOWER مشخص شدهاند.
توسعه در حال انجام است. رنگ زرد گرههایی را نشان میدهد که با RAISE مشخص شدهاند، و رنگ سبز نشان دهنده گرههایی است که با LOWER مشخص شدهاند.


بنبست دیگری رخ میدهد
[ویرایش]این بار نمیتوان از بنبست به راحتی عبور کرد. هیچیک از نقاط نمیتوانند مسیر جدیدی را از طریق همسایه به مقصد پیدا کنند؛ بنابراین، آنها به انتشار افزایش هزینههای خود ادامه میدهند. فقط نقاط خارج از کانال را میتوان یافت، که میتواند از طریق یک مسیر مناسب به مقصد منجر شود. به این ترتیب دو موج پایین توسعه مییابند که به صورت نقاطی که با اطلاعات مسیر جدید بعنوان غیرقابل دستیابی مشخص شدهاند، گسترش مییابد.
-
 کانال با اضافه شدن موانع مسدود شدهاست (قرمز)
کانال با اضافه شدن موانع مسدود شدهاست (قرمز) -
 گسترش در حال انجام است (موج Raise به رنگ زرد ، موج Lower به رنگ سبز)
گسترش در حال انجام است (موج Raise به رنگ زرد ، موج Lower به رنگ سبز) -
 مسیر جدید پیدا شد (به رنگ فیروزه ای)
مسیر جدید پیدا شد (به رنگ فیروزه ای)



Pseudocode
[ویرایش]while (!openList.isEmpty()) {
point = openList.getFirst();
expand(point);
}
Expand
[ویرایش]void expand(currentPoint) {
boolean isRaise = isRaise(currentPoint);
double cost;
for each (neighbor in currentPoint.getNeighbors()) {
if (isRaise) {
if (neighbor.nextPoint == currentPoint) {
neighbor.setNextPointAndUpdateCost(currentPoint);
openList.add(neighbor);
} else {
cost = neighbor.calculateCostVia(currentPoint);
if (cost <neighbor.getCost()) {
currentPoint.setMinimumCostToCurrentCost();
openList.add(currentPoint);
}
}
} else {
cost = neighbor.calculateCostVia(currentPoint);
if (cost <neighbor.getCost()) {
neighbor.setNextPointAndUpdateCost(currentPoint);
openList.add(neighbor);
}
}
}
}
Check for raise
[ویرایش]boolean isRaise(point) {
double cost;
if (point.getCurrentCost()> point.getMinimumCost()) {
for each(neighbor in point.getNeighbors()) {
cost = point.calculateCostVia(neighbor);
if (cost <point.getCurrentCost()) {
point.setNextPointAndUpdateCost(neighbor);
}
}
}
return point.getCurrentCost()> point.getMinimumCost();
}
انواع
[ویرایش]D متمرکز
[ویرایش]همانطور که از نام آن مشخص است، *D متمرکز یک الگوریتم گسترش یافته از *D است که از یک روش ابتکاری برای تمرکز انتشار RAISE و LOWER به سمت ربات استفاده میکند. به این ترتیب، فقط حالتهایی که مهم هستند به روز میشوند، به همان روشی که *A فقط هزینه برخی از گرهها را محاسبه میکند.
D* Lite
[ویرایش]D* Lite براساس *D اصلی یا *D متمرکز نیست، اما همان عمل را انجام میدهد. فهم آن سادهتر است و میتواند در تعداد کمتری خط کدش پیادهسازی و اجرا شود، از این رو نام آن "D* Lite" است. از نظر عملکرد، بهتر یا برابر با *D متمرکز است. D * Lite مبتنی بر برنامهریزی مادام العمر *A است که چند سال قبل توسط کونیگ و لیخاچف معرفی شد. D * آرشیو
حداقل هزینه در مقابل هزینه فعلی
[ویرایش]برای *D، تمایز بین حداقل هزینه و هزینههای فعلی مهم است. مورد اول فقط در زمان جمعآوری مهم است ولی مورد دوم بسیار حیاتی است زیرا OpenList را مرتب میکند. تابعی که حداقل هزینه را برمیگرداند همیشه کمترین هزینه به نقطه فعلی را برمیگرداند زیرا اولین ورودی OpenList است.
منابع
[ویرایش]- ↑ Stentz, Anthony (1994), "Optimal and Efficient Path Planning for Partially-Known Environments", Proceedings of the International Conference on Robotics and Automation: 3310–3317
- ↑ ۲٫۰ ۲٫۱ Stentz, Anthony (1995), "The Focussed D* Algorithm for Real-Time Replanning", Proceedings of the International Joint Conference on Artificial Intelligence: 1652–1659
- ↑ Hart, P.; Nilsson, N.; Raphael, B. (1968), "A Formal Basis for the Heuristic Determination of Minimum Cost Paths", IEEE Trans. Syst. Science and Cybernetics, SSC-4 (2): 100–107, doi:10.1109/TSSC.1968.300136
- ↑ Koenig, S.; Likhachev, M. (2005), "Fast Replanning for Navigation in Unknown Terrain", Transactions on Robotics, 21 (3): 354–363, doi:10.1109/tro.2004.838026
- ↑ Koenig, S.; Likhachev, M.; Furcy, D. (2004), "Lifelong Planning A*", Artificial Intelligence, 155 (1–2): 93–146, doi:10.1016/j.artint.2003.12.001
- ↑ Ramalingam, G.; Reps, T. (1996), "An incremental algorithm for a generalization of the shortest-path problem", Journal of Algorithms, 21 (2): 267–305, doi:10.1006/jagm.1996.0046
- ↑ Koenig, S.; Smirnov, Y.; Tovey, C. (2003), "Performance Bounds for Planning in Unknown Terrain", Artificial Intelligence, 147 (1–2): 253–279, doi:10.1016/s0004-3702(03)00062-6
- ↑ (Thesis).
{{cite thesis}}: Missing or empty|title=(help)